Содержание
- Журнал ВРМ World
- Введение в OLAP и многомерные базы данных
- Хранилища данных (место OLAP в информационной структуре предприятия)
- OLAP — удобный инструмент анализа
- Определение и основные понятия OLAP
- Тест FASMI
- OLAP = многомерное представление = Куб
- «Разрезание» куба
- Метки
- Иерархии и уровни
- Архитектура OLAP-приложений
- Технические аспекты многомерного хранения данных
- Что такое OLAP?
7. Обзор ИТ, предназначенных для оперативной и аналитической обработки данных
Успешно изучив материал, Вы будете знать:
-
понятие и основное назначение OLTP-систем;
-
понятие и основное назначение OLAP-систем;
-
классы OLAP-систем;
-
задачи, решаемые OLTP- и OLAP-системами.
После изучения данной темы Вы будете уметь:
-
отличать задачи, решаемые OLTP- и OLAP-системами;
-
ориентироваться в классах OLAP-систем.
После изучения материала Вы будете обладать навыками использования OLTP- и OLAP-системам в работе менеджера.
Основные понятия к теме 7
OLTP-система
OLAP-система
Data Warehousing — «хранилища (склады) данных»
В области ИТ управления существуют два взаимно дополняющих друг друга направления:
-
технологии, ориентированные на оперативную (транзакционную) обработку данных. Эти технологии лежат в основе КИСУ, предназначенных для оперативной обработки данных. Называются подобные системы — OLTP (online transaction processing) системы;
-
технологии, ориентированные на анализ данных и принятие решений. Эти технологии лежат в основе КИСУ, предназначенных для анализа накопленных данных. Называются подобные системы — OLAP (online analytical processing) системы.
7.1. OLAP-системы
Основное назначение OLAP-систем: динамический многомерный анализ исторических и текущих данных, стабильных во времени; анализ тенденций; моделирование и прогнозирование будущего. Такие системы, как правило, ориентированы на обработку произвольных, заранее не регламентированных запросов. В качестве основных характеристик этих систем можно отметить следующие:
-
поддержка многомерного представления данных, равноправие всех измерений, независимость производительности от количества измерений;
-
прозрачность для пользователя структуры, способов хранения и обработки данных;
-
автоматическое отображение логической структуры данных во внешние системы;
-
динамическая обработка разряженных матриц эффективным способом.
Термин OLAP часто отождествляют с системами поддержки принятия решений DSS (Decision Support Systems). А в качестве синонима термина «решения» используют Data Warehousing — «хранилища (склады) данных». Под этим понимается набор организационных решений, программных и аппаратных средств для обеспечения аналитиков информацией на основе данных из систем обработки транзакций нижнего уровня и других источников.
«Склады данных» позволяют обрабатывать данные, накопленные за длительные периоды времени. Эти данные являются разнородными (и не обязательно структурированными). Для «складов данных» присущ многомерный характер запросов. Огромные объемы данных, сложность структуры как данных, так и запросов — все это требует использования специальных методов доступа к информации.
В других источниках понятие Системы Поддержки Принятия Решений (СППР) считается более широким. Хранилища данных и средства оперативной аналитической обработки могут служить одними из компонентов архитектуры СППР.
OLAP всегда включает в себя интерактивную обработку запросов и последующий многопроходный анализ информации, который позволяет выявить разнообразные, не всегда очевидные тенденции, наблюдающиеся в предметной области.
Иногда различают OLAP в узком смысле — как системы, которые обеспечивают только выборку данных в различных разрезах, и OLAP в широком смысле, или просто OLAP, включающие в себя:
-
поддержку нескольких пользователей, редактирующих БД.
-
функции моделирования, в том числе вычислительные механизмы получения производных результатов, а также агрегирования и объединения данных;
-
прогнозирование, выявление тенденций и статистический анализ.
Каждый из этих типов систем требует специфической организации данных, а также специальных программных средств, обеспечивающих эффективное выполнение стоящих задач.
OLAP-средства обеспечивают проведение анализа деловой информации по множеству параметров, таких как вид товара, географическое положение покупателя, время оформления сделки и продавец, каждый из которых допускает создание иерархии представлений. Так, для времени можно пользоваться годовыми, квартальными, месячными и даже недельными и дневными промежутками; географическое разбиение может проводиться по городам, штатам, регионам, странам или, если потребуется, по целым полушариям.
OLAP-системы можно разбить на три класса.
1 класс. Наиболее сложными и дорогими из них являются основанные на патентованных технологиях серверы многомерных БД. Эти системы обеспечивают полный цикл OLAP-обработки и либо включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс, либо используют для анализа данных внешние программы работы с электронными таблицами. Продукты этого класса в наибольшей степени соответствуют условиям применения в рамках крупных информационных хранилищ. Для их обслуживания требуется целый штат сотрудников, занимающихся как установкой и сопровождением системы, так и формированием представлений данных для конечных пользователей. Обычно подобные пакеты довольно дороги. В качестве примеров продуктов этого класса можно привести систему Essbase корпорации Arbor Software, Express фирмы IRI (входящей теперь в состав Oracle), Lightship производства компании Pilot Software и др.
2 класс OLAP-систем — реляционные OLAP-системы (ROLAP). Здесь для хранения данных используются старые реляционные СУБД, а между БД и клиентским интерфейсом организуется определяемый администратором системы слой метаданных. Через этот промежуточный слой клиентский компонент может взаимодействовать с реляционной БД как с многомерной. Подобно средствам первого класса, ROLAP-системы хорошо приспособлены для работы с крупными информационными хранилищами, требуют значительных затрат на обслуживание специалистами информационных подразделений и предусматривают работу в многопользовательском режиме. Среди продуктов этого типа — IQ/Vision корпорации IQ Software, DSS/Server и DSS/Agent фирмы MicroStrategy и DecisionSuite компании Information Advantage.
ROLAP-средства реализуют функции поддержки принятия решений в надстройке над реляционным процессором БД.
Такие программные продукты должны отвечать ряду требований, в частности:
-
иметь мощный оптимизированный для OLAP генератор SQL-выражений, позволяющий применять многопроходные SQL-операторы SELECT и/или коррелированные подзапросы;
-
обладать достаточно развитыми средствами для проведения нетривиальной обработки, обеспечивающей ранжирование, сравнительный анализ и вычисление процентных соотношений в рамках класса;
-
генерировать SQL-выражения, оптимизированные для целевой реляционной СУБД, включая поддержку доступных в ней расширений этого языка;
-
предоставлять механизмы описания модели данных с помощью метаданных и давать возможность использовать эти метаданные для построения запросов в реальном масштабе времени;
-
включать в себя механизм, позволяющий оценивать качество построения сводных таблиц с точки зрения скорости вычисления, желательно с накоплением статистики по их использованию.
3 класс OLAP-систем — инструменты генерации запросов и отчетов для настольных ПК, дополненные OLAP-функциями или интегрированные с внешними средствами, выполняющими такие функции. Эти весьма развитые системы осуществляют выборку данных из исходных источников, преобразуют их и помещают в динамическую многомерную БД, функционирующую на ПК конечного пользователя. Указанный подход, позволяющий обойтись как без дорогостоящего сервера многомерной БД, так и без сложного промежуточного слоя метаданных, необходимого для ROLAP-средств, обеспечивает в то же время достаточную эффективность анализа. Эти средства для настольных ПК лучше всего подходят для работы с небольшими, просто организованными БД. Потребность в квалифицированном обслуживании для них ниже, чем для других OLAP-систем, и примерно соответствует уровню обычных сред обработки запросов. В числе основных участников этого сектора рынка — компания Brio Technology со своей системой Brio Query Enterprise, Business Objects с одноименным продуктом и Cognos с PowerPlay.
7.2. OLTP-системы
OLTP-системы, являясь высокоэффективным средством реализации оперативной обработки, оказались малопригодны для задач аналитической обработки. Это вызвано следующим.
-
Средствами традиционных OLTP-систем можно построить аналитический отчет и даже прогноз любой сложности, но заранее регламентированный. Любой шаг в сторону, любое нерегламентированное требование конечного пользователя, как правило, требует знаний о структуре данных и достаточно высокой квалификации программиста;
-
Многие необходимые для оперативных систем функциональные возможности являются избыточными для аналитических задач и в то же время могут не отражать предметной области. Для решения большинства аналитических задач требуется использование внешних специализированных инструментальных средств для анализа, прогнозирования и моделирования. Жесткая же структура баз не позволяет достичь приемлемой производительности в случае сложных выборок и сортировок и, следовательно, требует больших временных затрат для организации шлюзов.
-
В отличие от транзакционных, в аналитических системах не требуются и, соответственно, не предусматриваются развитые средства обеспечения целостности данных, их резервирования и восстановления. Это позволяет не только упростить сами средства реализации, но и снизить внутренние накладные расходы и, следовательно, повысить производительность при выборке данных.
7.3. Задачи, решаемые OLTP- и OLAP-системами
Таблица 7.1.
Задачи, решаемые OLTP- и OLAP-системами
|
Характеристика |
||
|
Частота обновления данных |
Высокая частота, небольшие «порции» |
Малая частота, большие «порции» |
|
Источники данных |
В основном внутренние |
По отношению к аналитической системе, в основном внешние |
|
Возраст данных |
Текущие (несколько месяцев) |
Исторически (за годы) и прогнозируемые |
|
Уровень агрегации данных |
Детализированные данные |
В основном агрегированные данные |
|
Возможности аналитических операций |
Регламентированные отчеты |
Последовательность интерактивных отчетов, динамическое изменение уровней агрегаций и срезов данных |
|
Назначение системы |
Фиксация, оперативный поиск и обработка данных, регламентированная аналитическая обработка |
Работа с историческими данными, аналитическая обработка, прогнозирование, моделирование |
Таблица 7.2.
Сравнение OLTP и OLAP
| Характеристика | ||
|
Преобладающие операции |
Ввод данных, поиск |
Анализ данных |
|
Характер запросов |
Много простых транзакций |
Сложные транзакции |
|
Хранимые данные |
Оперативные, детализированные |
охватывающие большой период времени, агрегированные |
|
Вид деятельности |
Оперативная, тактическая |
Аналитическая, стратегическая |
|
Тип данных |
Структурированные |
Разнотипные |
Основные выводы
-
В области ИТ управления существуют два взаимно дополняющих друг друга направления:
-
технологии, ориентированные на оперативную (транзакционную) обработку данных — OLTP (online transaction processing) системы;
-
технологии, ориентированные на анализ данных и принятие решений — OLAP (online analytical processing) системы.
-
-
Основное назначение OLAP-систем — динамический многомерный анализ исторических и текущих данных, стабильных во времени, анализ тенденций, моделирование и прогнозирование будущего.
OLAP-системы можно разбить на три класса.
1 класс. Серверы многомерных БД. Эти системы обеспечивают полный цикл OLAP-обработки и либо включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс, либо используют для анализа данных внешние программы работы с электронными таблицами.
2 класс. Реляционные OLAP-системы (ROLAP). Здесь для хранения данных используются старые реляционные СУБД, а между БД и клиентским интерфейсом организуется определяемый администратором системы слой метаданных. Через этот промежуточный слой клиентский компонент может взаимодействовать с реляционной БД как с многомерной.
3 класс. Инструменты генерации запросов и отчетов для настольных ПК, дополненные OLAP-функциями или интегрированные с внешними средствами, выполняющими такие функции. Эти системы осуществляют выборку данных из исходных источников, преобразуют их и помещают в динамическую многомерную БД, функционирующую на ПК конечного пользователя.
OLTP-системы, являясь высокоэффективным средством реализации оперативной обработки, оказались малопригодны для задач аналитической обработки.
Data Warehousing — «хранилища (склады) данных». Под этим понимается набор организационных решений, программных и аппаратных средств для обеспечения аналитиков информацией на основе данных из систем обработки транзакций нижнего уровня и других источников.
Контрольные вопросы
-
Какие два взаимно дополняющих друг друга направления существуют в области ИТ управления?
-
Сформулируйте основное назначение OLAP-систем
-
Сформулируйте основное назначение OL T P-систем
-
Что понимается под термином Data Warehousing?
Задания для самостоятельной работы
В тетради-практикуме выполните задания к теме 7.
Журнал ВРМ World
Классификация OLAP — программ
Сначала повторим общеизвестное определение OLAP. OLAP (On Line Analytical Processing) — процесс оперативного анализа — это класс программного обеспечения, предоставляющий пользователю возможность мгновенно, в режиме реального времени получать ответы на произвольные аналитические запросы.
Так сложилось, что не любые программы, которые быстро выполняют произвольные запросы, расчеты и выдают пользователю данные в понятном ему виде принято считать OLAP-средством. К классу OLAP относят только те программы, которые в качестве внешнего интерфейса предоставляют пользователю многомерную управляемую таблицу. Эта таблица позволяет пользователю менять местами колонки и строки, закрывать и раскрывать — описательные колонки, задавать условия фильтрации и при этом она автоматически вычисляет промежуточные в группах данных и окончательные итоги по — цифровым колонкам. Неотъемлемой частью OLAP-анализа является графическое отображение данных.
Программы, реализующие эту методику, делятся на следующие категории:
- OLAP-сервер или MOLAP-многомерная СУБД. Это машина вычислений и многомерная база данных, к которой обращаются клиентские программы с командами на получение данных и выполнение вычислений. В MOLAP хранятся — наборы данных, фактов и измерений, с заранее вычисленными агрегатами.
- MOLAP-компонента. Это инструмент программиста, при помощи которого разрабатываются клиентские программы, получающие вычисленные кубов от OLAP-сервера по какому-либо интерфейсу, например OLE DB for OLAP корпорации Microsoft.
- ROLAP-компонента. Это тоже инструмент программиста. В отличие от визуальной OLAP-компоненты она содержит собственную OLAP-машину для преобразования реляционных данных или многомерной матрицы в многомерные кубы. Другими словами, эта программа по запросу пользователя в оперативной памяти вычисляет агрегаты и сама же их отображает на экране.
- ROLAP-сервер. Относительно новый класс программного обеспечения. В отличие от OLAP-сервера не имеет в своем составе многомерной базы данных, а преобразует данные реляционной СУБД в многомерные кубы по запросу многих клиентских приложений.
- OLAP-программа. Это законченное решение, содержащее в своем составе OLAP-компоненту, средства описания произвольных запросов (Ad-hoc query) и интерфейс доступа к базам данных. В свою очередь такие программы можно разбить на две группы: MOLAP- и ROLAP-программы.
OLAP-компоненты
Любое конечное решение содержит OLAP-компоненту, которая является интерфейсом пользователя. Эти компоненты похожи друг на друга. Их визуальная часть состоит из элементов управления и элементов отображения данных. Как правило, это таблица, в полях которой содержаться данные, а колонки и строки являются элементами управления.
Подавляющее большинство поставщиков OLAP, а их в мире насчитывается около 140, не продают свои компоненты. Нам известно только три компоненты, которые можно купить для собственной разработки. Это Decision Cube компании Inprise в составе компиляторов Delphi и C++ Builder, Pivot Table корпорации Microsoft в составе MS Office, и Dynamic Cube компании Data Dynamic, специализирующейся на разработке OLAP-компонент.
Decision Cube компании Inprise поставляется как VCL-компонента. По нашей классификации относится к ROLAP-компонентам, то есть содержит в своем составе OLAP-машину и предназначен только для работы с реляционными СУБД или локальными таблицами. Он отличается весьма скромными возможностями. Например, в нем нельзя открыть один элемент измерения, или установить фильтр по нескольким измерениям, отобразить несколько фактов одновременно. Производительность компоненты невысока. Пределом является около 4000 записей при 5 измерениях. Компонента отображает в таблице одновременно только один факт. Неприятной особенностью является наличие в исходных текстах нескольких ошибок, в результате чего только высококвалифицированные программисты после исправления этих ошибок могут использовать компоненту в своих разработках. К достоинствам можно отнести простоту применения и освоения компоненты. При правильном использовании и небольших объемах данных продукты на базе этой компоненты могут оказаться полезными и приемлемыми по быстродействию.
Pivot Table корпорации Microsoft поставляется в двух вариантах: как составная часть MS Excel и как Web-компонента. Web-компонента (ActiveX) может быть использована как в браузере, так и собственном Windows-приложении. Pivot Table является одновременно и MOLAP- и ROLAP-компонентой. По протоколу OLE DB for OLAP он может взаимодействовать с многомерной СУБД MS OLAP Server, или другими 70-ю многомерными СУБД, разработчики которых поддержали этот протокол. По протоколу OLE DB Pivot Table может получать данные от реляционной СУБД и выполнять вычисления кубов в памяти. И конечно данные могут быть получены из заданной области таблицы MS Excel. В этом случае его производительность не отличается от производительности Decision Cube. Компонента отображает в таблице одновременно только один факт. Однако инструментарий компоненты шире, чем у Decision Cube — реализована произвольная фильтрация и раскрытие одного элемента измерения. Основным назначением компоненты является создание интерфейсов к OLAP-серверу в рамках концепции Business Intelligent корпорации Microsoft.
Dynamic Cube компании Data Dynamic является классической ROLAP-компонентой. Он поставляется как VCL для программистов Delphi и C++ Builder и как COM для приверженцев компонентной модели. OLAP- машина компоненты весьма мощна. Она с легкостью обрабатывает десятки и чуть медленнее даже сотни тысяч записей. Есть множественная фильтрация, открытие элемента одного измерения, некоторые дополнительные функции. Компонента позволяет отображать в таблице одновременно несколько фактов. Однако эта компонента довольно дорога, особенно впечатляет ее стоимость для профессиональных разработчиков.
Все три описанные выше компоненты по сравнению с готовыми продуктами многих поставщиков имеют весьма скупую функциональность, ограничивающуюся классическими функциями OLAP: drill down, move, rotate и пр. В то же время в некоторых готовых продуктах часто встречается инструментальная панель, наполненная кнопками дополнительных удобных функций. Таких как , и даже кнопками, выполняющими популярные аналитические задачи, например классический маркетинговый анализ 20/80.
Настольные OLAP-программы
Еще недавно поставщики OLAP-серверов продавали свои продукты по таким ценам, что их покупатели должны были быть богаты как арабские шейхи. Так, приобретение Oracle Express обошлось бы в $100 000 за рабочие места двух аналитиков и двух администраторов. Но, даже после выхода на рынок компании Microsoft, которая обрушила цены, предоставив OLAP-сервер бесплатно в составе MS SQL Server, создание Хранилищ данных или витрин данных остается серьезным мероприятием, требующим привлечения профессионального разработчика, администрирования в процессе эксплуатации и других расходов.
Поэтому на рынке появился особый класс продуктов — DOLAP (Desktop OLAP) — настольный OLAP. Это программа, которая устанавливается на каждый персональный компьютер. Она не требует сервера, имеет «нулевое администрирование». Программа позволяет пользователю настроиться на существующие у него базы данных; как правило, при этом создается словарь, скрывающий физическую структуру данных за ее предметным описанием, понятным специалисту. После этого программа выполняет произвольные запросы и результаты их отображает в OLAP-таблице. В этой таблице, в свою очередь, пользователь может манипулировать данными и получать на экране или на бумаге сотни различных отчетов.
По способу получения данных такие программы можно разделить на локальные и корпоративные:
- Локальные манипулируют данными таблицы MS Excel или небольших баз данных типа Access, DBF, Paradox.
- Корпоративные DOLAP имеют доступ к SQL-серверам или многомерным базам данных и, таким образом, тоже делятся на две категории.
Корпоративные DOLAP, предназначенные для анализа данных SQL-серверов позволяют анализировать уже имеющиеся в корпорации данные, хранящиеся в OLTP-системах. Однако вторым их назначением может быть быстрое и дешевое создание Хранилищ или витрин данных, когда программистам организации требуется лишь создать совокупности таблиц типа «звезда» и процедуры загрузки данных. Наиболее трудоемкая часть работы — разработка интерфейсов с многочисленными вариантами пользовательских запросов, интерфейсов и отчетов становится ненужной. Это буквально за несколько часов реализуется в DOLAP-программе. Освоение же такой программы конечным пользователем требует 30 минут.
DOLAP программы поставляются самими разработчиками баз данных, многомерных и реляционных. Это SAS Corporate Reporter, являющийся почти эталонным по удобству и красоте продуктом, Oracle Discovery, комплекс программ MS Pivot Services и Pivot Table и другие. Эти продукты, за исключением программ Microsoft, стоят недешево. Так SAS Corporate Reporter обойдется в $2000 на одного пользователя.
Большая группа программ поставляется в рамках компании «OLAP в массы», которую проводит корпорация Microsoft. Эти программы предназначены для работы с MS OLAP Services. Как правило, они являются улучшенными вариантами Pivot Table и предназначены для использования в рамках MS Office или Web. Это Matryx, Knosys и т.д.
Благодаря простоте, дешевизне и огромной эффективности этот класс продуктов приобрел огромную популярность на Западе. Большие корпорации строят свои Хранилища с распределенным доступом на основе таких программ.
OLAP-продукты компании «Intersoft Lab»
Контур Стандарт
Основным продуктом компании «Intersoft Lab» является большая информационно-управленческая система «Контур Корпорация», построенная по принципам Хранилища данных. Однако в процессе общения с клиентами компании осознала, что далеко не все готовы на инвестиции и организационные мероприятия, связанные с построением серьезного Хранилища данных. Первым шагом на этом пути для многих банков и предприятий мог бы стать OLAP-анализ данных из имеющихся OLTP-систем и собственных аналитических базах данных.
Для этих целей был создан DOLAP-продукт «Контур Стандарт».
Контур Стандарт 1.0 Первая версия системы относилась к классу локальных DOLAP. Средства программы позволяли организовать прямой доступ к dbf- и paradox-файлам. Кроме того, в состав дистрибутивного пакета входил мигратор данных, который помогал собрать в локальные таблицы данные из имеющихся у организации систем.
Контур Стандарт 2.0 В дальнейшем, для расширения мощности продукта в системе «Контур Стандарт» 2.0 был обеспечен и доступ к произвольным SQL-серверам на уровне таблиц и, что не встречается в зарубежных аналогах, хранимых процедур. Это превратило программу в корпоративную информационно-аналитическую систему. Отдельно был реализован интерфейс к системе «Контур Корпорация».
Одновременно для удобства администрирования программа была разделена на две редакции. Редакция «Developer» позволяет IT-специалисту описать источники данных и выборки. При этом создаются семантические словари, которые скрывают от конечного пользователя физический слой и переводят данные на язык предметной области. Редакция «Run-Time» позволяет анализировать данные и выпускать отчеты. Основным способом манипуляции данными является OLAP-компонента, которая позволяет без программирования и специальных навыков создавать необходимые отчеты. Одновременно были созданы и новые виды удобных аналитических инструментов, которые формально не являются OLAP-таблицами, но являются OLAP-средствами по духу, т.е. реализуют on-line анализ, но в другой форме представления данных.
В первых двух версиях применялась ROLAP-компонента Decision Cube компании Inprise. Однако ее невысокая мощность и функциональная упрощенность сдерживала применение программы в банках и организациях для анализа больших объемов данных. Поэтому было принято решение о ее замене. Маркетинговый анализ и ревизия интеллектуальных и производственных мощностей самой компании привели к решению о создании собственной OLAP-компоненты. В результате разработки компоненты, которую назвали Contour Cube, появилась следующая версия программы — «Контур Стандарт» 3.0, которая позволяет обрабатывать выборки данных до миллиона записей и обладает расширенной аналитической функциональностью.
Contour Cube
Компонента Contour Cube компании «Intersoft Lab» является представителем ROLAP-компонент. Она состоит из OLAP-машины, интерфейса доступа к данным, находящимся в SQL-серверах и других источниках, и визуальной части.
Компонента будет реализована в нескольких версиях для различных применений.
Версия VCL для использования в средах Delphi и C++ Builder компании Inprise. В этом случае данные поставляются через стандартный Data Set этих компиляторов. Доступ к источникам обеспечивается как при помощи BDE, так и ADO, поддержанной в последних версиях этих сред.
Версия COM предназначена для разработчиков на Visual Basic, Visual С++ и т.д. Она обеспечивает доступ к данным при помощи ADO. В будущих версиях будет поддержан и доступ к OLAP-серверам через интерфейс OLE DB for OLAP.
Версия ActiveX является Web-компонентой для создания аналитических Интернет-интерфейсов в стиле, предложенном Microsoft.
Версия DHTML состоит из сервера и DHTML-страниц. Она предназначена для создания аналитических Интернет-интерфейсов в среде UNIX, а также для бурно развивающегося рынка мобильных Интернет-устройств.
Основными достоинствами компоненты являются:
- Обработка больших объемов данных.
- Минимальные требования к памяти.
- Расширенная функциональность.
Высокие характеристики компоненты достигнуты за счет уникальной математической модели, созданной специалистами компании.
Создание множества версий компоненты стало возможно благодаря ее многослойной архитектуре. Слой OLAP Engine является относительно независимой частью компоненты. Он реализован как кросс-платформенная библиотека, имеющая API для различных слоев визуализации. Этот API обладает функциями загрузки данных, вычисления срезов многомерного куба и выполнения аналитических и сервисных функций. Сам слой OLAP Engine состоит из машины вычислений и абстрактного многомерного Хранилища данных, которое может сохраняться в виде файла для передачи другим пользователям или длительного использования.
Обработка больших объемов данных
Тесты на персональном компьютере с процессором Intel Celeron 400 и оперативной памятью 64 Мб дали следующие результаты. Загрузка 60 000 записей с 6-ю измерениями занимает 5 секунд; дальнейшие манипуляции, такие как полный поворот таблицы, drill down и drill up выполняются за десятые доли секунды.
Загрузка 500 000 записей с 7-ю измерениями занимает около 30 секунд, поворот такого куба выполняется в среднем за 2.5 секунды.
Это лучшие по порядку величины (sic!) результаты из известных нам OLAP-компонент. Так, Decision Cube и Pivot Table (без использования OLAP Services) требуют десятки секунд для загрузки и поворота таблицы объемом в 4000 записей и 6-ю измерениями. Скорость работы Dynamic Cube ниже, чем у Contour Cube, в среднем на 30% на средних объемах данных и в разы на предельных объемах.
Таким образом, во многих случаях благодаря своей мощности компонента делает необязательным использование OLAP-сервера. Это значительно упрощает процессы внедрения и администрирования корпоративной системы.
Минимальные требования к памяти
В момент работы с данными компонента занимает наименьший объем оперативной памяти по сравнению с одноклассниками. Так при загрузке 40 000 записей Contour Cube потребляет 7 МБ, Decision Cube 15 МБ.
Расширенная функциональность
В компоненте объединены функции лучших OLAP-компонент:
Уникальное свойство компоненты — алгоритм агрегации «Остаток счета». В связи с тем, что в основном OLAP-компоненты предназначаются для анализа продаж и других суммирующих видов анализов, они агрегируют по времени и остатки счетов. Это является ошибкой — остаток счета за квартал не является суммой остатков счета за день, а является остатком за последний день квартала. Реализация этого алгоритма позволяет использовать компоненту для анализа балансов и делает ее полезной не только для экономистов и маркетологов, но и для бухгалтеров.
Для того чтобы при использовании компоненты за минимальное время создавались мощные законченные продукты, в нее встроен набор часто встречающихся в реальной работе аналитических функций. Каждая из этих функций реализована как кнопка в инструментальной панели визуальной части компоненты. Вот перечень этих функций:
- Удалить нулевые колонки, удалить нулевые строки, удалить нулевые колонки и строки. Применяется для сжатия разреженных таблиц.
- Полный поворот. При этом колонки и строки таблицы меняются местами. Применяется для улучшения восприятия таблиц аналитиком, для подбора лучшей печатной формы.
- Фильтр по факту. Позволяет задать абсолютные граничные значения факта или количество наибольших или наименьших элементов. Является одним из инструментов факторного анализа.
- Кластерный анализ. Разбиение данных на заданное количество групп по предельным значениям факта. Например, разбиение клиентов на крупных, средних и мелких по объемам полученных от них доходов.
- 80/20. Популярная на Западе разновидность кластерного анализа в маркетинге. Пример ее применения: показать 20% клиентов, которые приносят 80% прибыли.
- Ранжирование. Генерация нового измерения «место в списке» по значению заданного факта и сортировка по нему. Полезно для анализа избирательных компаний, сравнения банков, предприятий, филиалов по заданному показателю.
- Отображение одновременно нескольких статистических итогов, таких как среднее, среднеквадратическое отклонение и т.д. Эта функция понравится продвинутым специалистам, особенно в области финансового, фондового анализа.
- Выгрузка в форматы MS Excel, MS Word, html. Позволяют продолжить анализ привычными средствами MS Excel, создать отчет произвольной формы, опубликовать отчет в Интернет.
В связи с невозможностью защиты авторских прав в России на программные продукты, физическая защита которых принципиально не реализуема, компонента как коммерческий продукт будет поставляться только на Западный рынок. Однако российские потребители могут воспользоваться ее достоинствами для развития собственного бизнеса в продуктах «Контур Стандарт» и «Контур Корпорация».
Введение в OLAP и многомерные базы данных
Михаил Альперович
Что такое OLAP сегодня, в общем-то знает каждый специалист. По крайней мере, понятия «OLAP» и «многомерные данные» устойчиво связаны в нашем сознании. Тем не менее тот факт, что эта тема вновь поднимается, надеюсь, будет одобрен большинством читателей, т. к. для того, чтобы представление о чем-либо с течением времени не устаревало, нужно периодически общаться с умными людьми или читать статьи в хорошем издании…
Хранилища данных (место OLAP в информационной структуре предприятия)
Термин «OLAP» неразрывно связан с термином «хранилище данных» (Data Warehouse).
Приведем определение, сформулированное «отцом-основателем» хранилищ данных Биллом Инмоном: «Хранилище данных — это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений».
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Зачем строить хранилища данных — ведь они содержат заведомо избыточную информацию, которая и так «живет» в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных «уголках» корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах. Автор имеет достаточно печальный опыт попыток «накормить» голодных аналитиков «сырыми» данными из оперативных систем — им это оказалось «не по зубам».
Таким образом, задача хранилища — предоставить «сырье» для анализа в одном месте и в простой, понятной структуре. Ральф Кимбалл в предисловии к своей книге «The Data Warehouse Toolkit» пишет, что если по прочтении всей книги читатель поймет только одну вещь, а именно: структура хранилища должна быть простой, — автор будет считать свою задачу выполненной.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
На мой взгляд, под хранилищем можно понимать не обязательно гигантское скопление данных — главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный термин — Data Marts (киоски данных), но в нашей российской практике его не часто услышишь.
OLAP — удобный инструмент анализа
Централизация и удобное структурирование — это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного — гибкости. Их нельзя «покрутить», «развернуть» или «свернуть», чтобы получить желаемое представление данных. Конечно, можно вызвать программиста (если он захочет придти), и он (если не занят) сделает новый отчет достаточно быстро — скажем, в течение часа (пишу и сам не верю — так быстро в жизни не бывает; давайте дадим ему часа три). Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше «срезов» и «разрезов» данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых «срезов». Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Компоненты, входящие в типичное хранилище, представлены на рис. 1.

Рис. 1. Структура хранилища данных
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Но мы тем самым рискуем наступить на уже описанные выше грабли, т. е. начать анализировать оперативные данные, которые напрямую для анализа непригодны.
Определение и основные понятия OLAP
Для начала расшифруем: OLAP — это Online Analytical Processing, т. е. оперативный анализ данных. 12 определяющих принципов OLAP сформулировал в 1993 г. Е. Ф. Кодд — «изобретатель» реляционных БД. Позже его определение было переработано в так называемый тест FASMI, требующий, чтобы OLAP-приложение предоставляло возможности быстрого анализа разделяемой многомерной информации ().
Тест FASMI
Fast (Быстрый) — анализ должен производиться одинаково быстро по всем аспектам информации. Приемлемое время отклика — 5 с или менее.
Analysis (Анализ) — должна быть возможность осуществлять основные типы числового и статистического анализа, предопределенного разработчиком приложения или произвольно определяемого пользователем.
Shared (Разделяемой) — множество пользователей должно иметь доступ к данным, при этом необходимо контролировать доступ к конфиденциальной информации.
Multidimensional (Многомерной) — это основная, наиболее существенная характеристика OLAP.
Information (Информации) — приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
OLAP = многомерное представление = Куб
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей — измерений (Dimensions) — находятся данные, количественно характеризующие процесс — меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п. Пользователь, анализирующий информацию, может «разрезать» куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
В качестве мер в трехмерном кубе, изображенном на рис. 2, использованы суммы продаж, а в качестве измерений — время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины — по странам, а данные о времени совершения операций — по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии) подробнее.
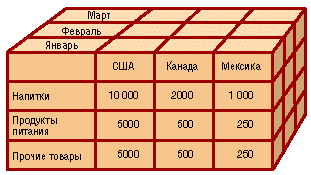
Рис. 2. Пример куба
«Разрезание» куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех? Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов.
Двумерное представление куба можно получить, «разрезав» его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, — и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) — другое, а в ячейках таблицы — значения мер. При этом набор мер фактически рассматривается как одно из измерений — мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую — значения единственного «неразрезанного» измерения).

Рис. 3. Двумерный срез куба для одной меры
На рис. 4 представлено лишь одно «неразрезанное» измерение — Store, но зато здесь отображаются значения нескольких мер — Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).

Рис. 4. Двумерный срез куба для нескольких мер
Двумерное представление куба возможно и тогда, когда «неразрезанными» остаются и более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений «разрезаемого» куба — см. рис. 5.

Рис. 5. Двумерный срез куба с несколькими измерениями на одной оси
Метки
Значения, «откладываемые» вдоль измерений, называются членами или метками (members). Метки используются как для «разрезания» куба, так и для ограничения (фильтрации) выбираемых данных — когда в измерении, остающемся «неразрезанным», нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения «Магазин» (Store) естественно объединяются в иерархию с уровнями:
All (Мир)
Country (Страна)
State (Штат)
City (Город)
Store (Магазин).
Архитектура OLAP-приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется.
Многомерность в OLAP-приложениях может быть разделена на три уровня:
- Многомерное представление данных — средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
- Многомерная обработка — средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
- Многомерное хранение — средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД, OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Технические аспекты многомерного хранения данных
Как уже говорилось выше, средства OLAP-анализа могут извлекать данные и непосредственно из реляционных систем. Такой подход был более привлекательным в те времена, когда OLAP-серверы отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и Informix, и Microsoft предлагают полноценные OLAP-серверы, и даже те IT-менеджеры, которые не любят разводить в своих сетях «зоопарк» из ПО разных производителей, могут купить (точнее, обратиться с соответствующей просьбой к руководству компании) OLAP-сервер той же марки, что и основной сервер баз данных.
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. Прежде чем рассмотреть эти способы, нам нужно поговорить о таком важном аспекте, как хранение агрегатов. Дело в том, что в любом хранилище данных — и в обычном, и в многомерном — наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью — ускорить выполнение запросов. Ведь, с одной стороны, в хранилище накапливается, как правило, очень большой объем данных, а с другой — аналитиков в большинстве случаев интересуют не детальные, а обобщенные показатели. И если каждый раз для вычисления суммы продаж за год пришлось бы суммировать миллионы индивидуальных продаж, скорость, скорее всего, была бы неприемлемой. Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются все суммарные показатели или их часть.
Но, как известно, за все надо платить. И за скорость обработки запросов к суммарным данным приходится платить увеличением объемов данных и времени на их загрузку. Причем увеличение объема может стать буквально катастрофическим — в одном из опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз! Степень «разбухания» данных при вычислении агрегатов зависит от количества измерений куба и структуры этих измерений, т. е. соотношения количества «отцов» и «детей» на разных уровнях измерения. Для решения проблемы хранения агрегатов применяются подчас сложные схемы, позволяющие при вычислении далеко не всех возможных агрегатов достигать значительного повышения производительности выполнения запросов.
Теперь о различных вариантах хранения информации. Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид — смешанный. Применяются следующие термины:
- MOLAP (Multidimensional OLAP) — и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
- ROLAP (Relational OLAP) — детальные данные остаются там, где они «жили» изначально — в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
- HOLAP (Hybrid OLAP) — детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий — объема данных, мощности реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема «разбухания» за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то бо/льшая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
Продолжение следует. В дальнейшем мы поговорим о конкретных OLAP-продуктах, выпускаемых ведущими производителями.
С автором статьи можно связаться по адресу: alperovich@digdes.com
Размещено с разрешения редакции PC Week/RE
Оригинал статьи в формате Microsoft Word
| Обсудить на форуме | Написать вебмастеру |
Что такое OLAP?
Первое четкое определение OLAP (On-line Analytical Processing) предложено в 1993 году Е.Ф.Коддом (E.F.Codd) в статье, опубликованной при поддержке Arbor Software (теперь — Hyperion Software). Статья включала 12 правил, которые сейчас уже стали широко известными и описаны на сайте любого поставщика OLAP приложений. Позже, в 1995 году, к ним были добавлены еще шесть менее известных правил, все они были разделены на четыре группы и названы «характеристиками» (features). Вот эти правила, дающие определение OLAP приложения с комментариями Найджела Пендса (Nigel Pendse), одного из создателей сайта OLAP Report.
Основные характеристики OLAP включают:
1. Многомерность модели данных. С этим утверждением мало кто спорит, и оно считается основной характеристикой OLAP. Частью этого требования считается возможность построения различных проекций и разрезов модели.
2. Интуитивные механизмы манипулирования данными. Кодд считает, что манипулирование данными должно производится с помощью действий непосредственно в ячейке таблиц, без применения меню или сложных. Можно предположить, что это подразумевает использование операций с мышью, но Кодд этого не утверждает. Многие продукты не выполняют этого правила. С нашей точки зрения, эта характеристика незначительно влияет на качество процесса анализа данных. Мы считаем, что программа должна предлагать возможность выбора модели работы, т.к. не всем пользователям нравится одно и то же.
3. Доступность. OLAP это Посредник. Кодд особенно подчеркивает, что ядро OLAP является программой промежуточного уровня между гетерогенными источниками данных и пользовательским интерфейсом. Большинство продуктов обеспечивают эти функции, но удобство доступа к данным часто оказывается ниже чем это хотелось бы другим поставщикам программ.
4. Пакетное извлечение данных. Это правило требует, чтобы продукты предлагали как собственные базы для хранения анализируемых данных, так и динамический (live) доступ к внешним данным. Мы согласны с Коддом в этом пункте и сожалеем, что лишь немногие OLAP продукты соответствуют ему. Даже те программы, которые предлагают такие функции, редко делают их легкими и достаточно автоматизированными. В результате, Кодд поддерживает многомерное представление данных плюс частичный предварительный обсчет больших многомерных баз данных с прозрачным сквозным доступом к детальной информации. Сегодня это рассматривается как определение гибридного OLAP, которая становится наиболее популярной архитектурой, так что Кодд очень точно увидел основные тенденции в этой области.
5. Архитектура «клиент-сервер». Кодд считает, что не только каждый продукт должен быть клиент-серверным, но и что каждая серверная компонента OLAP продуктов должна быть достаточно интеллектуальной для того, чтобы разные клиенты могли быть подключены с минимальными усилиями и программированием. Это намного более сложный тест, чем простая клиент-серверная архитектура и относительно мало продуктов проходит его. Мы могли бы возразить, что этот тест, возможно, сложнее, чем надо и не стоит диктовать разработчикам архитектуру системы.
6. Прозрачность. Этот тест также сложен, но необходим. Полное соответствие означает, что пользователь, скажем, электронной таблицы может получить полный доступ к средствам, предоставляемым ядром OLAP и может при этом даже не знать о том, откуда получены эти данные. Для того чтобы достичь этого, продукты должны предоставлять динамический доступ к гетерогенным источникам данных и полнофункциональный модуль, встраиваемый в электронную таблицу. Между электронной таблицей и хранилищем данных при этом размещается OLAP сервер.
7. Многопользовательская работа. Кодд определяет, что для того, чтобы считаться стратегическим OLAP инструментом, приложения должны работать не только на чтение и интерпретацию данных, и, соответственно, они должны обеспечивать одновременный доступ (включая и извлечение, и обновление данных), целостность и безопасность.
Специальные характеристики
8. Обработка ненормализованных данных. Это означает возможность интеграции между ядром OLAP и ненормализованным источником данных. Кодд выделяет то, что при обновлении данных, выполненном в среде OLAP, должна быть возможность изменять ненормализованные данные во внешних системах.
9. Хранение OLAP результатов отдельно от исходных данных. В действительности, это имеет отношение к реализации продукта, а не к его возможностям, но мало кто будет спорить с этим утверждением. По сути, Кобб поддерживает широко принятую систему, в соответствии с которой OLAP приложения должны строить анализ непосредственно на основе данных транзакции и изменения в данных OLAP должны храниться отдельно от данных транзакции.
10. Выделение отсутствующих данных. Это означает, что отсутствующие данные должны отличаться от нулевого значения. Как правило, все современные OLAP системы поддерживают эту характеристику.
11. Обработка отсутствующих значений. Все отсутствующие значения должны быть проигнорированы при анализе, вне зависимости от их источника.
Характеристики построения отчетов
12. Гибкое построение отчетов. Различные измерения должны выстраиваться любым способом в соответствии с потребностями пользователя. Большинство продуктов соответствует этому требованию в рамках специальных редакторов отчетов. Хотелось бы, чтобы такие же возможности были доступны и в интерактивных средствах просмотра, но это встречается значительно реже. Это — одна из причин, по которой мы предпочитаем, чтобы функционал анализа и построения отчетов был объединен в одном модуле.
13. Стабильная производительность при построении отчетов. Это означает, что производительность системы при построении отчетов не должна существенно падать при увеличении размерности или величины базы данных.
14. Автоматическое регулирование физического уровня. OLAP система должна автоматически регулировать физическую структуру для адаптации ее к типу и структуре модели.
Управление размерностью
15. Общая функциональность. Все измерения должны иметь одинаковые возможности в структуре и функциональности.
16. Неограниченное число измерений и уровней агрегирования. Фактически, под неограниченным числом Кодд подразумевает 15-20, т.е. число, заведомо превышающее максимальные потребности аналитика.
17. Неограниченные операции между данными различных измерений. Кодд полагает, что для того, чтобы приложение называлось многомерным, оно должно поддерживать любые вычисления с использованием данных всех измерений.
Подробности о продуктах Hyperion — на сайте www.hyperion.ru
Версия для печати
НАЗНАЧЕНИЕ, СОДЕРЖАНИЕ И ОСОБЕННОСТИ ПРИМЕНЕНИЯ OLAP – СИСТЕМ В ИНФОРМАЦИОННОМ МЕНЕДЖМЕНТЕ
1.1 ИНФОРМАЦИОННО-АНАЛИТИЧЕСКИЕ СИСТЕМЫ НА БАЗЕ OLAP-ТЕХНОЛОГИЙ Часто в компаниях существует несколько информационных систем – системы складского учета, бухгалтерские системы, ERP системы для автоматизации отдельных производственных процессов, системы сбора отчетности с подразделений компании, а также множество файлов, которые разбросаны по компьютерам сотрудников.
Имея столько разрозненных источников информации, часто бывает очень сложно получить ответы на ключевые вопросы деятельности компании и увидеть общую картину. А когда нужная информация все же находится в одной из используемых систем или локальном файле, то она часто оказывается устаревшей или противоречит информации, полученной из другой системы. Данная проблема эффективно решается с помощью информационно-аналитических систем, построенных на базе OLAP-техологий (другие названия: OLAP-система, Система бизнес-аналитики, Business Intelligence). OLAP (от англ. OnLine Analytical Processing — оперативная аналитическая обработка данных, также: аналитическая обработка данных в реальном времени, интерактивная аналитическая обработка данных) — подход к аналитической обработке данных, базирующийся на их многомерно-иерархическом представлении, являющийся частью более широкой области информационных технологий — бизнес-аналитики. Термин OLAP, предложенный Эдгаром Коддом (Edgar Codd) для разграничения таких систем с OLTP-системами (от англ. OnLine Transaction Processing — обработка транзакций в реальном времени), некоторые эксперты считают слишком широким. Поэтому Найджел Пендс (Nigel Pendse) предложил использовать для описания этой концепции и взамен предложенных Коддом 12-ти правил OLAP так называемый тест FASMI (от англ. Fast Analysis of Shared Multidimensional Information — быстрый анализ доступной многомерной информации), более точно харакетеризующую требования к этим системам. Fast (быстрый) отражает упомянутое выше требование к скорости реакции системы. По Пендсу, интервалы с момента инициации запроса до получения результата должен измеряться секундами. Важность этого требования возрастает при использовании таких систем в качестве инструмента оперативного представления данных для аналитика, так как длительное время ожидания может пагубно влиять на цепочку рассуждений аналитика. Analysis (анализ) предполагает приспособленность системы к использованию в релевантной для задачи и пользователя бизнес-логике с сохранением доступной «обычному» пользователю легкости оперирования данными без использования низкоуровневого специального инструментария. Shared (доступность, общедоступность) описывает очевидное требование к возможности одновременного многопользовательского доступа к информации с интегрированной системой разграничения прав доступа вплоть до уровня конкретной ячейки данных. Multidimensional (многомерность) является ключевым требованием концепции. Предполагается, что система должна обеспечивать полную поддержку многомерного иерархического представления как «наиболее логичного пути анализа бизнеса и организаций». Отметим, что многомерность указывает на модель концептуального представления данных, то есть на то, как пользователь должен представлять организацию данных при формулировании запросов, а не на то, в каких структурах хранятся данные физически. Многомерность в рамках OLAP предполагает концептуальное представление данных в виде многомерной структуры данных — гиперкуба (OLAP-куба), рёбрами в котором выступают измерения(dimension), а данные (facts — факты; measures —меры, показатели) расположены на пересечении осей измерений. Ключевую роль в управлении компанией играет информация. Как правило, даже небольшие компании используют несколько информационных систем для автоматизации различных сфер деятельности. Получение аналитической отчётности в информационных системах, основанных на традиционных базах данных сопряжено с рядом ограничений: — разработка каждого отчёта требует работы программиста; — отчёты формируются очень медленно (зачастую несколько часов), замедляя при этом работу всей информационной системы; — данные, получаемые от различных структурных элементов компании не унифицированы и часто противоречивы; — OLAP-системы, самой идеологией своего построения предназначены для анализа больших объёмов информации, позволяют преодолеть ограничения традиционных информационных систем;
1.2 КЛАССИФИКАЦИЯ OLAP-СИСТЕМ 1.2.1 ROLAP, Relational OLAP – реляционный OLAP
В реляционных OLAP-системах структура куба данных хранится в реляционной базе данных. Меры самого нижнего уровня остаются в реляционной витрине данных, служащей источником данных для куба. Предварительно обработанные агрегаты также хранятся в реляционной таблице. Когда человек, принимающий решение, запрашивает значение меры для определенного набора элементов измерения, ROLAP-система проверяет, указывают ли эти элементы на агрегат или на значение самого нижнего уровня иерархии (листовое значение). Если указан агрегат, то значение выбирается из реляционной таблицы. Если выбрано листовое значение, то значение берется из витрины данных. Благодаря реляционным таблицам, архитектура ROLAP позволяет хранить большие объемы данных. Поскольку в архитектуре ROLAP листовые значения берутся непосредственно из витрины данных, то возвращаемые ROLAP-системой листовые значения всегда будут соответствовать актуальному на данный момент положению дел. Другими словами, ROLAP-системы лишены запаздывания в части листовых данных Достоинства этого класса систем: — возможность использования ROLAP с хранилищами данных и различными OLTP-системами; — возможность манипулирования большими объемами данных; объем данных могут ограничивать только лежащие в основе ROLAP системы реляционных баз данных, подход ROLAP сам по себе не ограничивает объем данных; — безопасность и администрирование обеспечивается реляционными СУБД. Недостатки: — получение агрегатов и листовых данных происходит медленнее, чем, например, в MOLAP и HOLAP (см. ниже); — функциональность систем ограничивается возможностями SQL, так как аналитические запросы пользователя транслируются в SQL-операторы выборки; — сложно пересчитывать агрегированные значения при изменениях начальных данных; — сложно поддерживать таблицы агрегатов.
1.2.2 MOLAP, Multidimensional OLAP – многомерный OLAP
В многомерных OLAP-системах структура куба хранится в многомерной базе данных. В той же базе данных хранятся предварительно обработанные агрегаты и копии листовых значений. В связи с этим все запросы к данным удовлетворяются многомерной системой баз данных, что делает MOLAP-системы исключительно быстрыми. Для загрузки MOLAP-системы требуется дополнительное время на копирование в многомерную базу всех листовых данных. Поэтому возникают ситуации, когда листовые данные MOLAP-системы оказываются рассинхронизированными с данными в витрине данных. Таким образом, MOLAP-системы вносят запаздывание в данные нижнего уровня иерархии. Архитектура MOLAP требует большего объема дискового пространства из-за хранения в многомерной базе копий листовых данных. Но, несмотря на это, объем дополнительного пространства обычно не слишком велик, поскольку данные в MOLAP хранятся исключительно эффективно. Достоинства MOLAP-систем: — все данные хранятся в многомерных структурах, что существенно повышает скорость обработки запросов; — доступны расширенные библиотеки для сложных функций оперативного анализа; — обработка разреженных данных выполняется лучше, чем в ROLAP. Недостатки: — данные куба «оторваны» от базовой таблицы; необходимы специальные инструменты для формирования кубов и их пересчёта в случае изменения базовых значений; — сложно изменять измерения без повторной агрегации.
1.2.3 HOLAP, Hybrid OLAP – гибридный OLAP
В гибридных OLAP сочетаются черты ROLAP и MOLAP, отсюда и название – гибридный. В моделях HOLAP используются преимущества и минимизируются недостатки обеих архитектур. В HOLAP-системах структура куба и предварительно обработанные агрегаты хранятся в многомерной базе данных. Это позволяет обеспечить быстрое извлечение агрегатов из структур MOLAP. Значения нижнего уровня иерархии в HOLAP остаются в реляционной витрине данных, которая служит источником данных для куба. HOLAP не требует копирования листовых данных из витрины, хотя это и ведет к увеличению времени доступа при обращении к листовым данным. Данные в витрине доступны аналитику сразу после обновления. Таким образом, HOLAP-системы не вносят запаздывания в работу с данными нижнего уровня иерархии. По сути, HOLAP жертвует скоростью доступа к листовым данным ради устранения запаздывания при работе с ними и ускорения загрузки данных. В связи с этим HOLAP проигрывает по скорости MOLAP. К достоинствам подхода можно отнести комбинирование технологии ROLAP для разреженных данных и MOLAP для плотных областей, а к недостаткам – необходимость поддерживания MOLAP и ROLAP.
1.2.4 DROLAP, A Dense-Region Based Approach to OLAP – OLAP
По утверждениям авторов данного подхода, DROLAP превосходит ROLAP и MOLAP в эффективности управления пространством и обработки запросов. DROLAP заимствует преимущества ROLAP и MOLAP и комбинирует их для поддержки высокой скорости исполнения запросов и эффективности использования памяти. Основой DROLAP системы является использование плотных областей (dense regions) в кубах данных. Для этого используется алгоритм EDEM (Efficient Dense Region Mining). Также подход DROLAP лучше управляет не только дисковым пространством, но и кластеризованными многомерными данными.
1.2.5 RTOLAP, R-ROLAP или Real-time ROLAP
Иногда этот подход называют по-другому – Real-Time Analytical Processing или RAP. RTOLAP отличается от ROLAP, в основном, тем, что для хранения агрегатов не создаются дополнительные реляционные таблицы, а агрегаты рассчитываются в момент запроса. Только явно введенные данные сохраняются в многомерном кубе. При выполнении запроса пользователя сервер выбирает данные либо рассчитывает значения. Все вычисления выполняются по требованию, а все данные находятся в основной памяти. Достоинства подхода RTOLAP: — не существует угрозы «взрыва» данных, так как в кубе не сохраняются предварительно вычисленные значения; — вычисления по требованию позволяют не перегружать основную память RAM. Недостатки: — ограниченность хранения и обработки куба данных объемом основной памяти; — снижение скорости обработки из-за вычислений по требованию.
1.2.6 DOLAP, Desktop OLAP
DOLAP является одноуровневой технологией OLAP. В данной архитектуре OLAP можно скачать относительно небольшие кубы данных из центральной точки (витрины или хранилища данных) и выполнять многомерный анализ, отключившись от этого ресурса. В другом варианте пользователь может сам создать OLAP-куб, не подключаясь к серверу. Достоинства подхода DOLAP: — дружественный (user friendly) подход для манипулирования данными в локальном режиме; — высокая скорость обработки запросов; — низкая стоимость; — удобный инструмент для пользователей, которые не могут постоянно поддерживать соединение с хранилищем данных; — наиболее простое развертывание продуктов из всех подходов к организации OLAP. Недостатки: — ограниченная функциональность; — ограничение на объем данных.
1.2.7 WOLAP, Web-based OLAP
Архитектура WOLAP предполагает использование возможностей Web. WOLAP-системы выполняют аналитические функции, такие как агрегирование и детализация, обеспечивают высокую производительность в сочетании со всеми преимуществами, которые дает Web-приложение. При использовании таких систем значительно облегчается задача установки, конфигурирования и развертывания. Web-приложение выполняется на сервере, и поэтому на клиентской машине нужны только браузер и подключение к Intranet/Internet. Подобная стратегия развертывания особенно удобна для администраторов хранилищ данных, которым часто приходится работать с широким контингентом удаленных пользователей, что очень не просто при использовании традиционной клиент/серверной архитектуры. К достоинствам подхода WOLAP можно отнести следующее: — обучение OLAP сводится к минимуму за счет использования хорошо знакомых Internet-функций и методов навигации; — обеспечивавется поддержка OLAP, независимая от платформы; — развертывание программного обеспечения обходится крайне дешево; — реализация решений WOLAP основывается на технологиях HTML, Java, ActiveX, а также их комбинациях.
1.3 ОСНОВНЫЕ ПРЕИМУЩЕСТВА OLAP-СИСТЕМ
Ключевое требование, предъявляемое к OLAP-системам — скорость, позволяющая использовать их в процессе интерактивной работы аналитика с информацией. Преимущества OLAP-систем следующие: — предметная ориентированность, означает, что в кубах собрана информация по различным аспектам деятельности организации: закупкам, продажам и т.п. Это отличает базы OLAP от оперативных БД, где данные организованы в соответствии с различными процессами, такими, как, например, оформление и выписка документов, оформление заказов и др.; — многопользовательский режим работы, клиент-серверная архитектура OLAP-продуктов обеспечивает одновременный доступ большого числа пользователей. При этом анализ производится одинаково быстро по всем аспектам информации независимо от размера и сложности структуры БД; — прямой доступ к данным позволяет пользователю видеть сразу всю информацию, не отфильтрованную отчетами. То есть, если пользователь видит документ, например, со странной датой исполнения (например, накладная, датированная 5200 годом), то это означает, что такой документ реально существует в исходной (оперативной) базе; — cоосредоточение необходимых данных в одном месте, отражает ту особенность, что вся аналитика, например, факта продажи (контрагент, менеджер, дата, вид сделки и прочее) хранится в том же кубе и доступ к ней не требует дополнительного обращения к каким-то внешним источникам (справочникам и т.п.); — удобные средства доступа, просмотра и анализа деловой информации. Пользователь получает интуитивно понятную модель данных, организуя их в виде многомерных кубов. Это позволяет ему проводить как сравнительный анализ показателей, так анализ различных сценариев по принципу «что-если», построенных на основе прогнозных и статистических данных компании; — удобная навигация по данным, как правило, с использование мышки; — разнообразные инструменты для обработки данных, встроенные функции агрегации, ранжирования, сортировок, вычисления, правило Парето (80/20) и т.д.; — визуализация информации, от того насколько удобно для восприятия пользователя будут представлены срезы, зависит качество анализа информации; — on-line функционирование обеспечивает выявление ассоциаций, закономерностей, трендов, проведение классификации, обобщения или детализации, составление прогнозов, т. е. предоставляет инструмент для управления предприятием в реальном времени; — простота освоения и использования сводных таблиц, мало найдется пользователей, которые не работали бы с Excel. Excel – как один из вариантов OLAP-клиента очень прост в использовании. Сводные таблицы Excel легко воспринимаются. И требуют незначительных навыков в работе с ними; — неизменность данных, позволяет формировать и в дальнейшем использовать для анализа массивы заранее обработанных данных (предвычисленные индексы), потому что OLAP-системы работают не с оперативными базами данных, а со стратегическими архивами, отличающимися низкой частотой обновления, интегрированностью, хронологичностью и предметной ориентированностью. Именно неизменность данных и позволяет вычислять их промежуточное представление, ускоряющее анализ гигантских объемов информации; — хорошая оперативность в отличие от классических методов поиска запросы формируются не на основе жестко заданных (или требующих для модификации вмешательства программиста и, следовательно, времени) форм, а с помощью гибких нерегламентированных подходов; — быстрая детализация итоговых данных просматривая сводные таблицы, пользователь видит сначала итоговые значения показателей (например, за период или по группе), и в случае необходимости может их легко детализировать (например, по 2005 году, по первому кварталу); — высокая скорость формирования отчетов, скорость выполнения OLAP – в десятки раз отличается от обычных. Дело в том, что в OLAP-кубах расчет необходимых данных происходит заранее, и при формировании отчета пользователь ждет только вывода данных. Любой сложности OLAP – отчеты строятся не более 5-10 секунд; — высокая точность отчетов, многие сталкивались с «не состыковкой» данных: по вине дефекта учетной программы или из-за того, что учет велся параллельно в нескольких учетных системах. Например, когда не совпадают итоговые значения в разных разрезах. В OLAP-отчетов таких ситуаций не возникает. Поэтому всем данным OLAP-отчета можно доверять; — возможность самостоятельного формирования нужных отчетов в отличие от традиционных программ, которые выводят таблицу строго определенной формы и содержания, OLAP-технологии дают пользователю сформировать тот отчет, который ему необходим в данный момент. Пользователь может развернуть данные по произвольной аналитике, посмотреть их более или менее подробно (например, разложить по дням данные за месяц или же посмотреть те же цифры поквартально), вывести или же убрать какие-то показатели, сформировать иерархические заголовки таблицы и многое другое; — возможность сведения данных из разных базЕсли в компании несколько подразделений с разной структурой БД и разными учетными программами, то OLAP-отчетность позволяет свести данные, консолидировать их; — отсутствие привлечения программистов на текущие задачи. Для того чтобы пользоваться OLAP-отчетностью, необходимо сформулировать один раз требования к ней. После этого специалист создаст механизмы наполнения ХД. На основании данных пользователь может сам создавать необходимые отчеты. Один отчет может заменять несколько отчетов простой системы. Легкость оперирования данными в OLAP–отчетах позволяет сохранить деньги на создании многих обычных отчетов. Не требуется оплачивать обучение, потому как пользоваться Excel могут практически все. Таким образом, OLAP-системы входят в состав подавляющего большинства решений для бизнес-аналитики, «корпоративных» редакций СУБД основных поставщиков (IBM, Microsoft, Oracle). В той или иной мере технологии OLAP используются в существенной части современных ERP-систем. Итоги внедрения OLAP-систем таковы, что руководство в результате получает полное ясное видение ситуации и единый механизм учета, контроля и анализа. С другой стороны, за счет автоматизации внутренних бизнес-процессов и повышения производительности сотрудников, уменьшается потребность в человеческих ресурсах.